In a relational database model, the structure of data is maintained through a defined schema. A relational schema serves as the framework that outlines how data is organized and managed within a relational database. It includes attributes and the relationships between them. This framework ensures that data is stored in a way that maintains consistency and integrity.
In this chapter, we will explore relational database schemas in depth, understand key concepts through examples, and explain how constraints help maintain data reliability.
Relational Database Schema
A relational database schema, represented by S, acts as a map for how data is structured in the database. It consists of a set of relation schemas and a collection of integrity constraints.
The schema outlines how data interacts within and between tables. Each relation schema specifies the table’s name, its attributes, and their domains.
Components of a Schema
A relational schema has three major components:
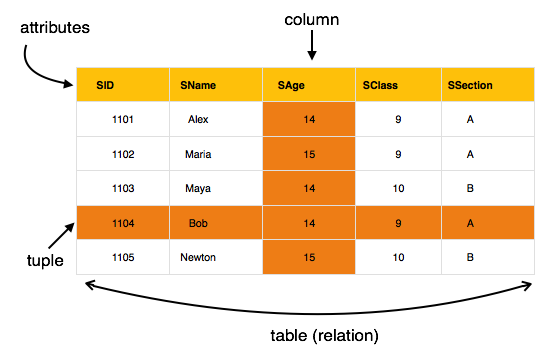
- Relation Schema (R) − The structure of a table, written as R(A1, A2, …, An), where A1, A2, …, An are attributes.
- Attribute − A column within a table, each with a specific domain that limits the type of data it can contain.
- Database State (DB) − The current data held in all tables conforming to the schema. A valid state meets all schema constraints.
Example − Consider a relational schema for a COMPANY database:
- EMPLOYEE (Ssn, Name, Salary, Dno)
- DEPARTMENT (Dnumber, Dname, Mgr_ssn, Mgr_start_date)
- PROJECT (Pnumber, Pname, Plocation, Dnum)
Each relation schema outlines the columns of its respective table. It also indicates how data should be represented.
Relational Database Schemas – Key Features and Components
Let us now understand some of the key features and components of Relational Database Schemas:
Attributes and Their Domains
Every attribute within a relation schema has an associated domain that defines its allowable values. The domains enforce data type restrictions and value limits, ensuring consistency within the database.
Consider an example where the Ssn attribute in the EMPLOYEE table might be limited to a pattern that matches valid social security numbers (e.g., XXX-XX-XXXX). Similarly the Age attribute could be restricted to integer values between 18 and 65.
We know domains help prevent errors by ensuring the supplied data conforms to expected types and formats. So, an Age attribute defined with INTEGER CHECK (Age BETWEEN 18 AND 65) would block an insertion of Age = 17 or Age = 70.
Relation States
A relation state is the set of tuples (rows) that exist in a table at any given time. Each tuple must comply with the attribute domains defined in the schema.
For a better understanding, consider the following EMPLOYEE table with data:
| Fname | Lname | Ssn | Salary | Dno |
|---|---|---|---|---|
| John | Smith | 123456789 | 30000 | 5 |
| Franklin | Wong | 333445555 | 40000 | 5 |
| Alicia | Zelaya | 999887777 | 25000 | 4 |
| Jennifer | Wallace | 987654321 | 43000 | 4 |
| Ramesh | Narayan | 666884444 | 38000 | 5 |
| Joyce | English | 453453453 | 25000 | 5 |
| Ahmad | Jabbar | 987987987 | 25000 | 4 |
| James | Borg | 888665555 | 55000 | 1 |
For example, a tuple in the EMPLOYEE table might be represented as,
<John, Smith,123-45-6789,30000,5>
This tuple states that John Smith, identified by his Ssn, earns a salary of $30,000 and works in the department with Dno = 5. (We have removed other attributes for simplicity)
Integrity Constraints
Integrity constraints make sure that the data remains accurate and logically consistent. Integrity constraints include:
- Key Constraints − Enforce uniqueness for specified attributes, known as keys, so that no two tuples share the same values for these attributes.
- Entity Integrity − Ensures primary key attributes cannot have NULL values, maintaining the uniqueness and identifiability of each tuple.
- Referential Integrity − Ensures foreign keys match primary keys in related tables or are NULL.
| Dname | Dnumber | Mgr_ssn | Mgr_start_date |
|---|---|---|---|
| Research | 5 | 333445555 | 1988-05-22 |
| Administration | 4 | 987654321 | 1995-01-01 |
| Headquarters | 1 | 888665555 | 1981-06-19 |
In the COMPANY database, the Dno attribute in the EMPLOYEE table is a foreign key referencing the Dnumber attribute in the DEPARTMENT table. If an EMPLOYEE record has Dno = 5, Dnumber = 5 must exist in the DEPARTMENT table for referential integrity to hold.
Practical Examples of Relational Database Schemas
Let us go through the COMPANY database schema and see how the tables relate and enforce constraints.
Here is the PROJECT table:
| Pname | Pnumber | Plocation | Dnum |
|---|---|---|---|
| ProductX | 1 | Bellaire | 5 |
| ProductY | 2 | Sugarland | 5 |
| ProductZ | 3 | Houston | 5 |
| Computerization | 10 | Stafford | 4 |
| Reorganization | 20 | Houston | 1 |
| Newbenefits | 30 | Stafford | 4 |
- EMPLOYEE (Ssn, Name, Salary, Dno) − The Ssn attribute acts as the primary key, uniquely identifying each employee. The Dno attribute is a foreign key referencing Dnumber in the DEPARTMENT table.
- DEPARTMENT (Dnumber, Dname, Mgr_ssn, Mgr_start_date) − The Dnumber attribute is the primary key, uniquely identifying each department. The Mgr_ssn attribute references Ssn in the EMPLOYEE table, indicating which employee manages the department.
- PROJECT (Pnumber, Pname, Plocation, Dnum) − Pnumber serves as the primary key. Dnum is a foreign key referencing Dnumber in DEPARTMENT.
If an employee record is inserted with Dno = 10, but Dnumber = 10 does not exist in the DEPARTMENT table, the insertion will be rejected due to a referential integrity violation.
Super Keys and Candidate Keys
Super keys and candidate keys help identify unique tuples within a relation.
- The term “super key” is used for any combination of attributes that uniquely identifies a tuple.
- A candidate key is a minimal super key without redundant attributes.
Consider a CAR schema:
CAR (License_number, Engine_serial_number, Make, Model)
In this case,
- License_number is a candidate key, as it uniquely identifies each car.
- License_number, Engine_serial_number together is a superkey, but not minimal, so it is not a candidate key.
The Importance of Primary Keys
A primary key is nothing but a chosen candidate key. It must have unique, non-NULL values. This constraint ensures every record can be uniquely identified.
For example, Ssn is the primary key in the EMPLOYEE table. Trying to insert a record with Ssn = NULL will violate entity integrity, resulting in a rejected insertion.
Relationships and Foreign Keys
Foreign keys are attributes in one table that link to primary keys in another. Foreign keys are meant for creating relationship between tables. They help ensure consistency when dealing with related data.
Consider the WORKS_ON table with attributes Essn and Pno:
| Essn | Pno | Hours |
|---|---|---|
| 123456789 | 1 | 32.5 |
| 123456789 | 2 | 7.5 |
| 666884444 | 3 | 40.0 |
| 453453453 | 1 | 20.0 |
| 453453453 | 2 | 20.0 |
| 333445555 | 2 | 10.0 |
| 333445555 | 3 | 10.0 |
| 333445555 | 10 | 10.0 |
| 333445555 | 20 | 10.0 |
| 999887777 | 30 | 30.0 |
| 999887777 | 10 | 10.0 |
| 987987987 | 10 | 35.0 |
| 987987987 | 30 | 5.0 |
| 987654321 | 30 | 20.0 |
| 987654321 | 20 | 15.0 |
| 888665555 | 20 | NULL |
Essn references Ssn in EMPLOYEE, and Pno references Pnumber in PROJECT. This relationship defines which employees are working on which projects.
Violation Case − If an employee’s Ssn is deleted from EMPLOYEE but still exists as Essn in WORKS_ON, then referential integrity gets violated unless action is taken (e.g., cascading the delete or setting Essn to NULL).
Conclusion
To conclude, relational database schemas are foundational for defining how data is structured and managed. In this chapter, we highlighted the components of a schema, such as relation schemas, attributes, and their domains. Thereafter, we used the COMPANY schema to illustrate the importance of primary and foreign keys. We also understood how integrity constraints like entity and referential integrity help maintain data reliability.