Let us first understand what software engineering stands for. The term is made of two words, software and engineering.
Software is more than just a program code. A program is an executable code, which serves some computational purpose. Software is considered to be collection of executable programming code, associated libraries and documentations. Software, when made for a specific requirement is called software product.
Engineering on the other hand, is all about developing products, using well-defined, scientific principles and methods.
Software engineering is an engineering branch associated with development of software product using well-defined scientific principles, methods and procedures. The outcome of software engineering is an efficient and reliable software product.
Definitions
IEEE defines software engineering as:
(1) The application of a systematic,disciplined,quantifiable approach to the development,operation and maintenance of software; that is, the application of engineering to software.
(2) The study of approaches as in the above statement.
Fritz Bauer, a German computer scientist, defines software engineering as:
Software engineering is the establishment and use of sound engineering principles in order to obtain economically software that is reliable and work efficiently on real machines.
Software Evolution
The process of developing a software product using software engineering principles and methods is referred to as software evolution. This includes the initial development of software and its maintenance and updates, till desired software product is developed, which satisfies the expected requirements.
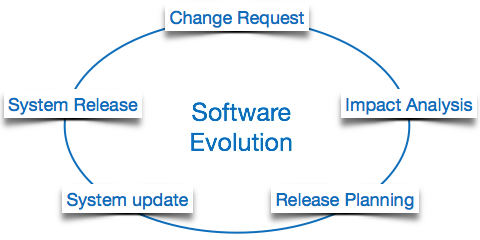
Evolution starts from the requirement gathering process. After which developers create a prototype of the intended software and show it to the users to get their feedback at the early stage of software product development. The users suggest changes, on which several consecutive updates and maintenance keep on changing too. This process changes to the original software, till the desired software is accomplished.
Even after the user has desired software in hand, the advancing technology and the changing requirements force the software product to change accordingly. Re-creating software from scratch and to go one-on-one with requirement is not feasible. The only feasible and economical solution is to update the existing software so that it matches the latest requirements.
Software Evolution Laws
Lehman has given laws for software evolution. He divided the software into three different categories:
- S-type (static-type) – This is a software, which works strictly according to defined specifications and solutions. The solution and the method to achieve it, both are immediately understood before coding. The s-type software is least subjected to changes hence this is the simplest of all. For example, calculator program for mathematical computation.
- P-type (practical-type) – This is a software with a collection of procedures. This is defined by exactly what procedures can do. In this software, the specifications can be described but the solution is not obvious instantly. For example, gaming software.
- E-type (embedded-type) – This software works closely as the requirement of real-world environment. This software has a high degree of evolution as there are various changes in laws, taxes etc. in the real world situations. For example, Online trading software.
E-Type software evolution
Lehman has given eight laws for E-Type software evolution –
- Continuing change – An E-type software system must continue to adapt to the real world changes, else it becomes progressively less useful.
- Increasing complexity – As an E-type software system evolves, its complexity tends to increase unless work is done to maintain or reduce it.
- Conservation of familiarity – The familiarity with the software or the knowledge about how it was developed, why was it developed in that particular manner etc. must be retained at any cost, to implement the changes in the system.
- Continuing growth- In order for an E-type system intended to resolve some business problem, its size of implementing the changes grows according to the lifestyle changes of the business.
- Reducing quality – An E-type software system declines in quality unless rigorously maintained and adapted to a changing operational environment.
- Feedback systems- The E-type software systems constitute multi-loop, multi-level feedback systems and must be treated as such to be successfully modified or improved.
- Self-regulation – E-type system evolution processes are self-regulating with the distribution of product and process measures close to normal.
- Organizational stability – The average effective global activity rate in an evolving E-type system is invariant over the lifetime of the product.
Software Paradigms
Software paradigms refer to the methods and steps, which are taken while designing the software. There are many methods proposed and are in work today, but we need to see where in the software engineering these paradigms stand. These can be combined into various categories, though each of them is contained in one another:
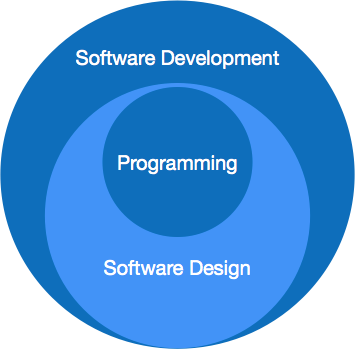
Programming paradigm is a subset of Software design paradigm which is further a subset of Software development paradigm.
Software Development Paradigm
This Paradigm is known as software engineering paradigms where all the engineering concepts pertaining to the development of software are applied. It includes various researches and requirement gathering which helps the software product to build. It consists of
- Requirement gathering
- Software design
- Programming
Software Design Paradigm
This paradigm is a part of Software Development and includes
- Design
- Maintenance
- Programming
Programming Paradigm
This paradigm is related closely to programming aspect of software development. This includes
- Coding
- Testing
- Integration
Need of Software Engineering
The need of software engineering arises because of higher rate of change in user requirements and environment on which the software is working.
- Large software – It is easier to build a wall than to a house or building, likewise, as the size of software become large engineering has to step to give it a scientific process.
- Scalability- If the software process were not based on scientific and engineering concepts, it would be easier to re-create new software than to scale an existing one.
- Cost- As hardware industry has shown its skills and huge manufacturing has lower down he price of computer and electronic hardware. But the cost of software remains high if proper process is not adapted.
- Dynamic Nature- The always growing and adapting nature of software hugely depends upon the environment in which user works. If the nature of software is always changing, new enhancements need to be done in the existing one. This is where software engineering plays a good role.
- Quality Management- Better process of software development provides better and quality software product.
Characteristics of good software
A software product can be judged by what it offers and how well it can be used. This software must satisfy on the following grounds:
- Operational
- Transitional
- Maintenance
Well-engineered and crafted software is expected to have the following characteristics:
Operational
This tells us how well software works in operations. It can be measured on:
- Budget
- Usability
- Efficiency
- Correctness
- Functionality
- Dependability
- Security
- Safety
Transitional
This aspect is important when the software is moved from one platform to another:
- Portability
- Interoperability
- Reusability
- Adaptability
Maintenance
This aspect briefs about how well a software has the capabilities to maintain itself in the ever-changing environment:
- Modularity
- Maintainability
- Flexibility
- Scalability
In short, Software engineering is a branch of computer science, which uses well-defined engineering concepts required to produce efficient, durable, scalable, in-budget and on-time software products.