Dennis Ritchie and Ken Thompson developed the C programming language in 1972, primarily to re-implement the Unix kernel. Because of its features such as low-level memory access, portability and cross-platform nature etc., C is still extremely popular. Most of the features of C have found their way in many other programming languages.
The development of C has proven to be a landmark step in the history of computing. Even though different programming languages and technologies dominate today in different application areas such as web development, mobile apps, device drivers and utilities, embedded systems, etc., the underlying technologies of all of them are inspired by the features of C language.
The utility of any technology depends on its important features. The features also determine its area of application. In this chapter, we shall take an overview of some of the significant features of C language.
C is a Procedural and Structured Language
C is described as procedure-oriented and structured programming language. It is procedural because a C program is a series of instructions that explain the procedure of solving a given problem. It makes the development process easier.
In C, the logic of a process can be expressed in a structured or modular form with the use of function calls. C is generally used as an introductory language to introduce programming to school students because of this feature.
C is a General-Purpose Language
The C language hasn’t been developed with a specific area of application as a target. From system programming to photo editing software, the C programming language is used in various applications.
Some of the common applications of C programming include the development of Operating Systems, databases, device drivers, etc.
C is a Fast Programming Language
C is a compiler-based language which makes the compilation and execution of codes faster. The source code is translated into a hardware-specific machine code, which is easier for the CPU to execute, without any virtual machine, as some of the other languages like Java need.
The fact that C is a statically typed language also makes it faster compared to dynamically typed languages. Being a compiler-based language, it is faster as compared to interpreter-based languages.
C is Portable
Another feature of the C language is its portability. C programs are machine-independent which means that you can compile and run the same code on various machines with none or some machine-specific changes.
C programming provides the functionality of using a single code on multiple systems depending on the requirement.
C is Extensible
C is an extensible language. It means if a code is already written, you can add new features to it with a few alterations. Basically, it allows adding new features, functionalities, and operations to an existing C program.
Standard Libraries in C
Most of the C compilers are bundled with an extensive set of libraries with several built-in functions. It includes OS-specific utilities, string manipulation, mathematical functions, etc.
Importantly, you can also create your user-defined functions and add them to the existing C libraries. The availability of such a vast scope of functions and operations allows a programmer to build a vast array of programs and applications using the C language.
Pointers in C
One of the unique features of C is its ability to manipulate the internal memory of the computer. With the use of pointers in C, you can directly interact with the memory.
Pointers point to a specific location in the memory and interact directly with it. Using the C pointers, you can interact with external hardware devices, interrupts, etc.
C is a Mid-Level Programming Language
High-level languages have features such as the use of mnemonic keywords, user-defined identifiers, modularity etc. C programming language, on the other hand, provides a low-level access to the memory. This makes it a mid-level language.
As a mid-level programming language, it provides the best of both worlds. For instance, C allows direct manipulation of hardware, which high-level programming languages do not offer.
C Has a Rich Set of Built-in Operators
C is perhaps the language with the most number of built-in operators which are used in writing complex or simplified C programs. In addition to the traditional arithmetic and comparison operators, its binary and pointer related operators are important when bit-level manipulations are required.
Recursion in C
C language provides the feature of recursion. Recursion means that you can create a function that can call itself multiple times until a given condition is true, just like the loops.
Recursion in C programming provides the functionality of code reusability and backtracking.
User-defined Data Types in C
C has three basic data types in int, float and char. However, C programming has the provision to define a data type of any combination of these three types, which makes it very powerful.
In C, you can define structures and union types. You also have the feature of declaring enumerated data types.
Preprocessor Directives in C
In C, we have preprocessor directives such as #include, #define, etc. They are not the language keywords. Preprocessor directives in C carry out some of the important roles such as importing functions from a library, defining and expanding the macros, etc.
File Handling in C
C language doesn’t directly manipulate files or streams. Handling file IO is not a part of the C language itself but instead is handled by libraries and their associated header files.
File handling is generally implemented through high-level I/O which works through streams. C identifies stdin, stdout and stderr as standard input, output and error streams. These streams can be directed to a disk file to perform read/write operations.
These are some of the important features of C language that make it one of the widely used and popular computer languages.




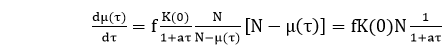


 , where β0 β1is the initial failure intensity and β0-1 is dubbed failure intensity decay parameter.
, where β0 β1is the initial failure intensity and β0-1 is dubbed failure intensity decay parameter.
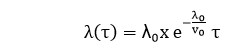





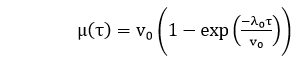





 hr. Determine the current failure intensity.
hr. Determine the current failure intensity.












