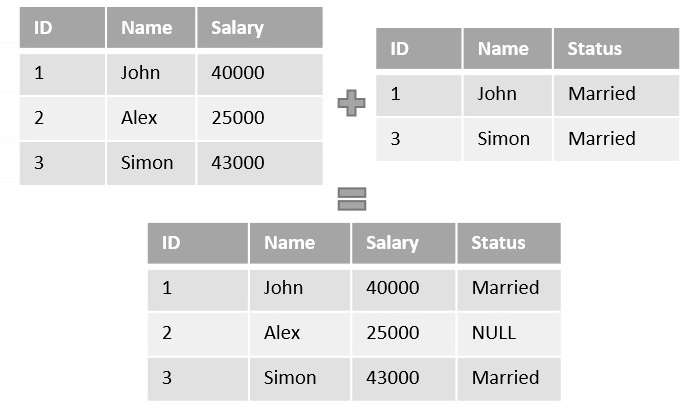
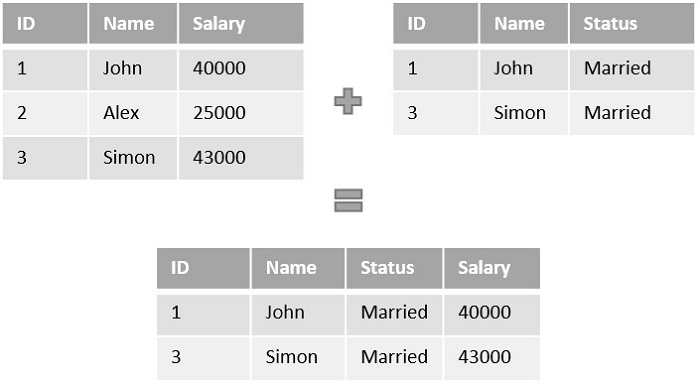
What is Class Binding?
A dynamic web application usually have dynamic styles and are set during the runtime of the application. Class binding is a special binding to bind a dynamic value to the class attribute of a HTML element.
Let us see more details about class binding in this chapter.
Ways to use Class Binding
Angular provides four different ways to implement class binding. Each of them supports a special feature. The four ways are as follows:
- Single class binding
- Single class binding with on/off feature
- Multiple style binding
- Multiple style binding through an object with on/off feature
Let us learn one by one in the upcoming sections.
Single Class Binding
In single class binding, class string should be surrounded by square bracket and a template variable should be set as it’s value.
<div [class]="<template variable>"><!-- content --></div>Here, the template variable holds the class name for the specific HTML element.
Single Class Binding with on/off Feature
In single class binding with on/off feature, class style should be appended by the actual class name of the given HTML element and a template variable with boolean value should be set as it’s value. The boolean value determines the availability of the specific class to the HTML element.
<div [class.<class name>]="template variable">
<!-- content --></div>Here, the template variable outputs either true or false.
Let us consider a class with name red, used to set the text of the HTML element to red color.
.red{color: red;}
Consider a member variable, isRedEnabled available in the component.
isRedEnabled: boolean =true
Then, the class binding can be set in a HTML element as shown below −
<div [class.red]="isRedEnabled"><!-- content --></div>
Multiple Class Binding
In multiple class binding, class string should be surrounded by square bracket and the value should be set with one of more existing class name separated by space. For example, two class (myClass and myAnotherClass) for a HTML element can be set using [class] as shown below −
<div [class]="<template variable>"><!-- content --></div>
Here, the template variable will emit myClass myAnotherClass string.
Multiple Class Binding through an Object with on/off Feature
In multiple class binding through an object with on/off feature, class string should be surrounded by square bracket and the value should be set with an object of type Record<string, boolean> having keys and values with class name and boolean value respectively. The boolean value of a key determine whether the corresponding key will be set a class of the given HTML element.
<div [class]="<objects as template variable>"><!-- content --></div>
Let as consider an object with multiple keys representing class name and have boolean values as shown below −
// in component
myClass: Record<string, boolean>={
c1:true,
c2:false
c3:true}
Apply the class binding in the template as shown below −
// in template <div [class]="myClass"><!-- content --></div>
Then the output will have c1 and c3 class because both of these classes have true value in the object.
// output <div class="c1 c3"><!-- content --></div>
Implementing Class Binding
Let us create a simple registration form to understand class binding. Our registration form will have three input field as shown below and a button to submit the registration form.
1. Username 2. Password 3. Confirm password
Step 1: Create a new application, my-app using angular CLI as shown below −
ng newmy-app
Step 2: Create a new registration form component, RegisterForm using angular CLI as shown below −
ng generate component RegisterForm
Step 3: Next, open the registration form component’s template and add a form with username, password and confirm password.
<div><form method="post"><div class="container"><label for="username"><b>Username</b></label><input type="text" name="username" required><label for="password"><b>Password</b></label><input type="password" name="password" required><label for="confirm_password"><b>Confirm Password</b></label><input type="password" name="confirm_password" required><button type="submit">Register</button></div></form></div>
Step 4: Open the registration form component’s CSS style and style the form using CSS as shown below −
.container{padding: 15px;}input[type=text], input[type=password]{width: 100%;padding: 10px 20px;margin: 10px 0;display: inline-block;border: 1px solid #ccc;box-sizing: border-box;}button{background-color: blue;color: white;padding: 15px 20px;margin: 10px 0;border: none;cursor: pointer;width: 100%;}
Step 5: Include our registration form component in the app template file, app.component.html
<app-register-form />
Step 6: Run the application and test the registration form.
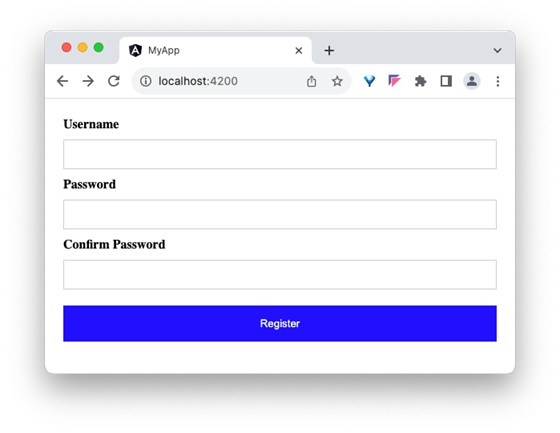
Step 7: Next, let us create few classes in the style file and apply our new class for the button using class binding.
Step 8: Next, add two class, purple and smallcaps in the component’s style file.
.purple{background-color: purple;}.smallcaps{font-variant: small-caps;}
Step 9: Add a member variable, isPurple in the component as shown below −
isPurple: boolean =true
Step 10: Next, add an object in the component with purple and smallcaps class as keys as shown below −
btnClass: Record<string, boolean>={'purple':true,'smallcaps':true}
Step11: Next, assign the variable, isPurple to the button through class binding.
<button type="submit"[class.purple]="isPurple">Register</button>
Step12: Run the application and check the output. Output will show the button with purple color.
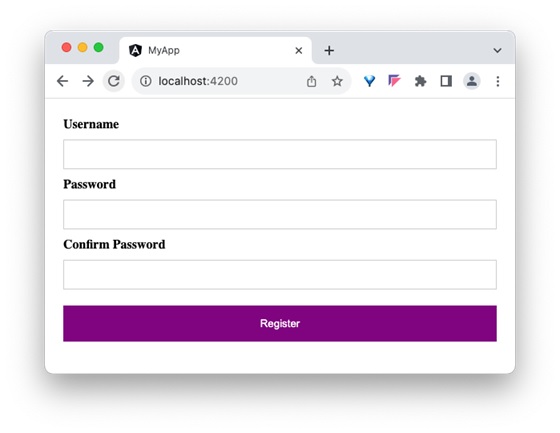
Step13: Next, reassign the object, btnClass to the buttons class through class binding.
<button type="submit"[class]="btnClass">Register</button>Here, both purple and small caps will be applied.
Step14: Run the application and check the output. Output will show the button with purple color and Register text is small caps format.

Step15: The complete listing of the component is as follows,
import{ Component }from'@angular/core';
@Component({
selector:'app-login-form',
templateUrl:'./register-form.component.html',
styleUrls:['./register-form.component.css']})exportclassRegisterFormComponent{
isPurple: boolean =true
btnClass: Record<string, boolean>={'purple':true,'smallcaps':true}}
Step16: The complete listing of the component’s template is as follows,
<div><form method="post"><div class="container"><label for="username"><b>Username</b></label><input type="text" name="username" required><label for="password"><b>Password</b></label><input type="password" name="password" required><label for="confirm_password"><b>Confirm Password</b></label><input type="password" name="confirm_password" required><!-- <button type="submit" [class.purple]="isPurple">Register</button> --><button type="submit" [class]="btnClass">Register</button></div></form></div>
Style binding
Style binding in Angular allows you to dynamically set inline CSS styles on an HTML element based on the component’s properties or template variables.
Syntax of Style Binding
Angular provides four different syntax in style binding. Each type of style binding supports a special feature. The four syntax as are follows:
- Single style binding
- Single style binding with unit
- Multiple style binding
- Multiple style binding through a custom style object