Angular directives are classes that enhance the feature of a HTML element or component and add additional behavior to the web application. They can transform a static HTML page into dynamic by manipulating DOM. They begin with ng, which stands for Angular.
The @directive decorator is used to mark a TypeScript class as an Angular Directive. This decorator contains some configuration metadata that determines how the directive should be processed, instantiated and used at runtime.
HTML DOM model is constructed as a tree of objects. It is a standard object model to access HTML elements.
Features and Uses of Angular Directives
Following are the features and uses of Angular Directives −
- Using directives, you can create your custom HTML elements, attributes and classes.
- They allow developers to create the required features once and reuse them across different parts of the Angular application.
- It became easy to update and maintain the code as we didn’t need to write code for the same feature again and again.
- Directives can control the DOM elements.
Types of Directives
Directives are categorized based on the type of feature it provides to the HTML element/component. The type of directive and its purpose are as follows:
- Components: Component is basically a type of directive. As we know, they can generate a a piece of HTML document in memory (DOM structure), called View. The view will have both design and event based dynamic functionality.
- Attribute directives: Attribute directives provides additional feature to a HTML element/component (host) with respect to appearance and behavior. For example, a menu component attached to a attribute directive can show next level of menu upon hovering the component.
- Structural directives: Structural directives can change the entire layout of the host HTML element/component by adding or removing the component’s DOM elements.

Structural Directives
Structural directives change the structure of DOM by adding or removing elements. It is denoted by an asterisk (*) symbol with three pre-defined directives ngIf, ngFor and ngSwitch. Let’s understand one by one in brief.
The list of commonly used structural directives are:
- ngIf − This directive is used to display or hide data in your application. When the given condition becomes TRUE, it will display the data, otherwise not. We can add this to any tag in our template.
- ngFor − ngFor is used to repeat a portion of elements from the given list of items.
- ngSwitch − It checks multiple conditions.
Attribute Directives
Attribute directives change the appearance or behavior of DOM elements or components. It is used just like a normal HTML attribute. However, the directive should be enclosed within square brackets [ ] to bind it to the element.
The most commonly used attribute directives are as follows:
- ngStyle − It is used to add dynamic styles.
- ngClass − It adds or removes CSS classes in HTML elements.
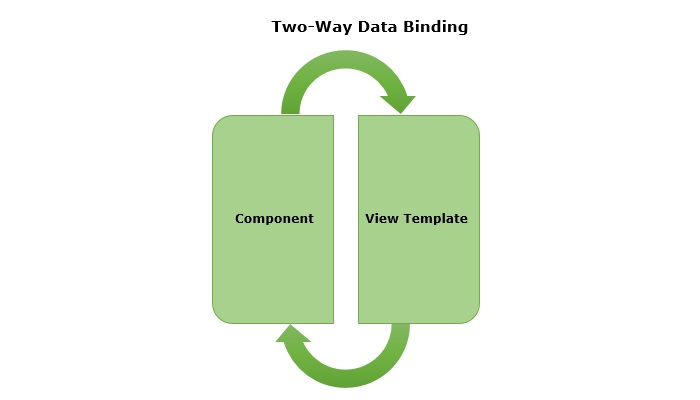
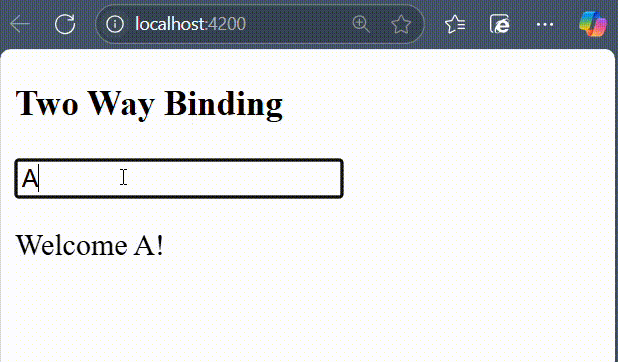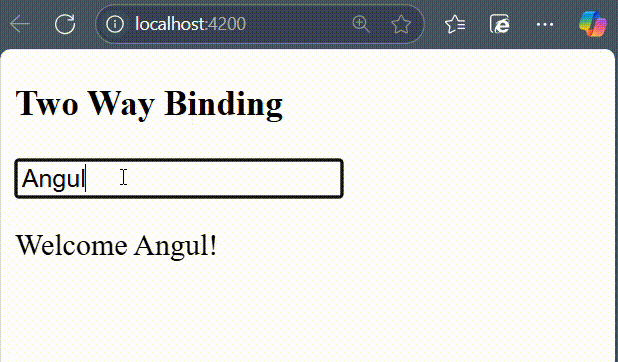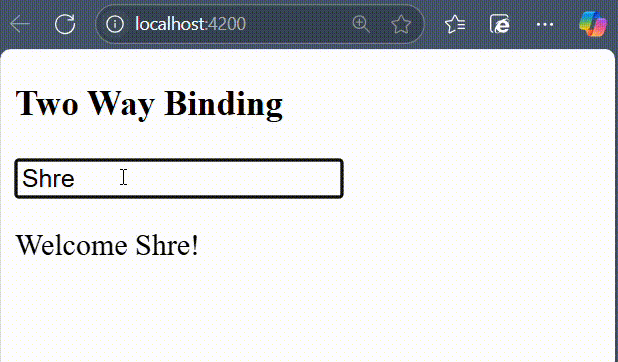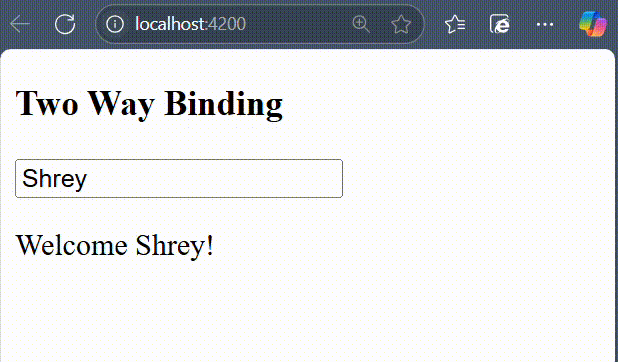
- ngModel − This directive is used for two-way binding.
Component Directives
Each component of an Angular application is a directive itself. It is a special directive with Views. Also, it has @Input and @Output decorator to send and receive information between parent and child components.
Syntax
To create a component for your Angular application, use the command given below −
ng generate component component-name
Difference between Component and Directive
The table below shows how Components are different from Directives −
| Components | Directives |
|---|---|
| Components in Angular are used to create UI elements and manage their state. | Directives in Angular are classes that can modify the behavior or appearance of existing DOM elements. |
| They create reusable UI elements. | They create reusable features and behaviors for certain elements. |
| The @Component decorator is used to declare a Component. | The @Directive decorator is used to declare a Directive. |
| There is only one component for each DOM element. | There can be one or more directives for each DOM element. |
Custom Directives
A custom directive is a user-defined directive that allows developers to extend the functionality of HTML elements. The attribute and structural built-in directives (covered in previous two chapters) offers very basic and pre-defined functionalities. However, with custom directives, you can add specific behaviors to HTML elements based on project requirements, user interactions, or changes in data.
To create a custom directive, run the following command in Angular CLI −
ng generate directive <directive-name>